今天遇到有人跟我說 EC2 的服務無法使用,我當下以為跟以前一樣是因為某台機器可能剛好卡了一下,因此就直接在 AWS 上按下系統重啟,結果系統竟然沒有重啟我就直接按下停止。結果機器啟動之後就出現 Status check 1/2 的狀況,重啟了幾次發現都是一樣的狀況我就請 Support 幫忙查了一下,不過因為沒有購買 AWS Support 所以沒有辦法進一步查詢問題。

在沒有辦法的情況下我只能打開 Get instance screenshot 看一下狀況
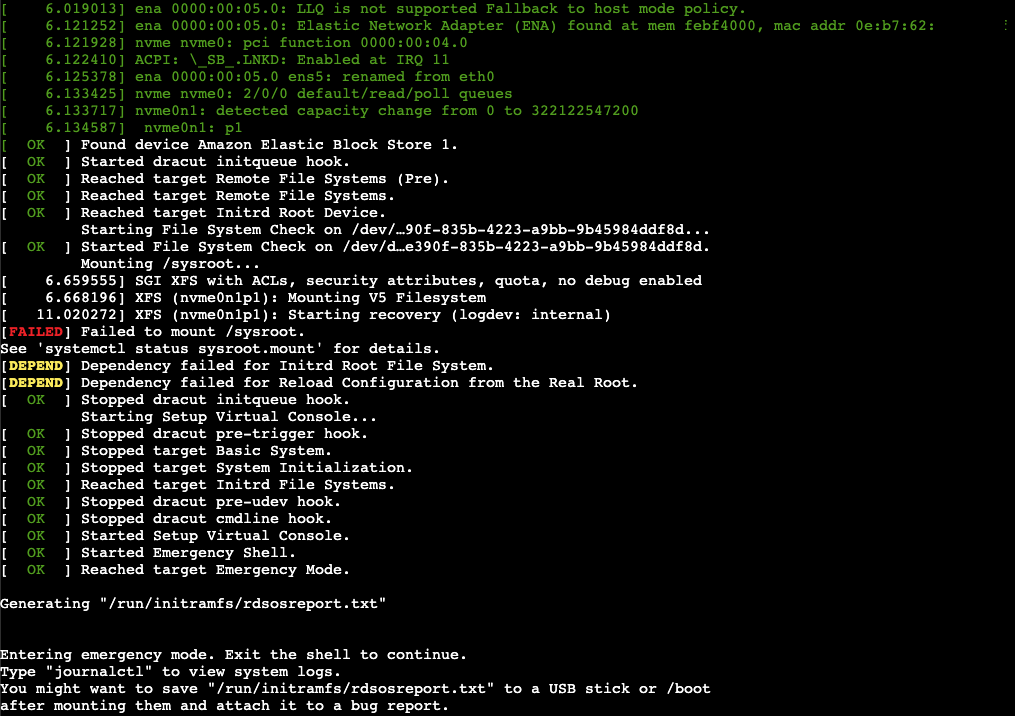
系統無法 mount /sysroot
看完之後好像也沒看到什麼狀況就點了下面的 Connect 進去看看狀況,看了一下大事不妙系統在 mount /sysroot 的時候竟然失敗難怪沒辦法啟動。
[ OK ] Started File System Check on /dev/d…e390f-835b-4223-a9bb-9b45984ddf8d.
Mounting /sysroot...
[ 6.659555] SGI XFS with ACLs, security attributes, quota, no debug enabled
[ 6.668196] XFS (nvme0n1p1): Mounting V5 Filesystem
[ 11.020272] XFS (nvme0n1p1): Starting recovery (logdev: internal)
[FAILED] Failed to mount /sysroot.
See 'systemctl status sysroot.mount' for details.
[DEPEND] Dependency failed for Initrd Root File System.
[DEPEND] Dependency failed for Reload Configuration from the Real Root.
解決方法
出現這個問題的解決方法是開一台新的 EC2 Instance 然後把這顆有問題的硬碟用資料碟的方法掛載起來,然後修復它。
修復方法
使用 lsblk 檢查有問題的硬碟代號
[ec2-user@ip-172-31-10-10 ~]$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 259:0 0 8G 0 disk ├─nvme0n1p1 259:3 0 8G 0 part / └─nvme0n1p128 259:4 0 1M 0 part nvme1n1 259:1 0 300G 0 disk └─nvme1n1p1 259:2 0 280G 0 part
使用指令檢查硬碟發現它真的有問題
[ec2-user@ip-172-31-10-10 ~]$ sudo xfs_repair -v /dev/nvme1n1p1
Phase 1 - find and verify superblock...
- reporting progress in intervals of 15 minutes
- block cache size set to 172200 entries
Phase 2 - using internal log
- zero log...
zero_log: head block 5405 tail block 7092
ERROR: The filesystem has valuable metadata changes in a log which needs to
be replayed. Mount the filesystem to replay the log, and unmount it before
re-running xfs_repair. If you are unable to mount the filesystem, then use
the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount
of the filesystem before doing this.
使用修復硬碟指令修復硬碟
[ec2-user@ip-172-31-10-10 ~]$ sudo xfs_repair -v -L /dev/nvme1n1p1
Phase 1 - find and verify superblock...
- reporting progress in intervals of 15 minutes
- block cache size set to 172200 entries
Phase 2 - using internal log
- zero log...
zero_log: head block 5405 tail block 7092
ALERT: The filesystem has valuable metadata changes in a log which is being
destroyed because the -L option was used.
- scan filesystem freespace and inode maps...
agi unlinked bucket 20 is 414292 in ag 30 (inode=126243412)
agi unlinked bucket 55 is 1652663 in ag 59 (inode=249116599)
sb_icount 2286464, counted 2291648
sb_ifree 27750, counted 23431
sb_fdblocks 11511530, counted 11353049
- 10:51:18: scanning filesystem freespace - 141 of 141 allocation groups done
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- 10:51:18: scanning agi unlinked lists - 141 of 141 allocation groups done
- process known inodes and perform inode discovery...
- agno = 0
- agno = 105
- agno = 90
- agno = 60
...
- agno = 140
- traversal finished ...
- moving disconnected inodes to lost+found ...
disconnected inode 126243412, moving to lost+found
disconnected inode 249116599, moving to lost+found
Phase 7 - verify and correct link counts...
- 10:51:51: verify and correct link counts - 141 of 141 allocation groups done
Note - quota info will be regenerated on next quota mount.
Maximum metadata LSN (87058:5395) is ahead of log (1:2).
Format log to cycle 87061.
XFS_REPAIR Summary Tue Dec 27 10:51:52 2022
Phase Start End Duration
Phase 1: 12/27 10:51:17 12/27 10:51:17
Phase 2: 12/27 10:51:17 12/27 10:51:18 1 second
Phase 3: 12/27 10:51:18 12/27 10:51:35 17 seconds
Phase 4: 12/27 10:51:35 12/27 10:51:36 1 second
Phase 5: 12/27 10:51:36 12/27 10:51:37 1 second
Phase 6: 12/27 10:51:37 12/27 10:51:51 14 seconds
Phase 7: 12/27 10:51:51 12/27 10:51:51
Total run time: 34 seconds
done
修復成功後再把硬碟掛回去原本的 EC2 開機就會發現系統正常可以啟動了!我一直以為我不會在雲端上面執行這種修復的說